Wanquan Feng (冯万泉)Researcher @ ByteDance Seed Team
Multimodal AI / Video Generation / World Model
|

|
Short Bio
I am currently a researcher at the ByteDance Seed Team, focusing on multimodal AI, especially video generation.
From July 2022 to November 2023, I served as a researcher at the Kling Team, Y-tech, Kuaishou Technology (Kwai Inc.). I earned my Ph.D. degree in 2022 from School of Mathematical Sciences at University of Science and Technology of China (USTC), under the guidance of Prof. Juyong Zhang. Prior to my doctorate, I obtained my bachelor's degree from USTC in 2016.
NOTE: As of 2026, my research interests primarily focus on VIDEO GENERATION (follow-up version of Seedance) and WORLD MODEL. I welcome discussions on related topics; let's collaborate and strive for progress together (✿◠‿◠)
News
-
[2026-02] Two papers accepted to CVPR 2026.
-
[2025-06] One paper accepted to ICCV 2025.
-
[2025-04] Code of HyperLoRA released.
-
[2025-02] Code of AR-Diffusion released.
-
[2025-02] Four papers accepted to CVPR 2025.
-
[2025-01] Code of DeTeCtive released.
-
[2024-12] One paper accepted to ICLR 2025.
-
[2024-11] Received the 'Breakthrough in New Areas' award of ByteDance Intelligent Creation in 2024-Q3.
-
[2024-09] One paper accepted to NeurIPS 2024.
-
[2023-12] Joined ByteDance.
-
▼ Show More
Publications & Preprints (* equal contribution, † corresponding author)
2026

Hongrui Cai, Junjie Luo, Zhihong Fu, Shengnan Zhu, Jiawei Wen, Wanquan Feng †, Songtao Zhao, Qian He
CVPR 2026.
[Paper][Project Page]

Mengtian Li, Jinshu Chen, Songtao Zhao, Wanquan Feng, Pengqi Tu, Qian He
CVPR 2026.
[Paper][Project Page]
2025
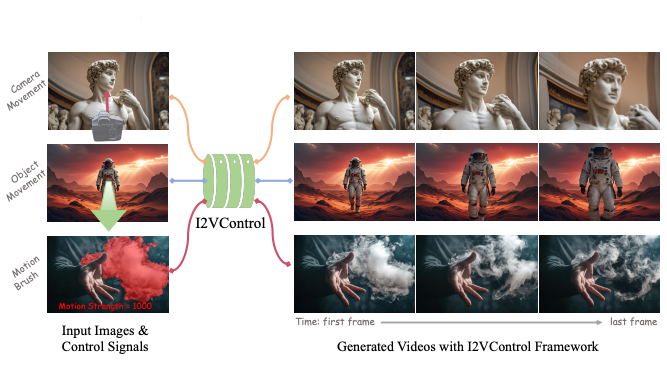
Wanquan Feng †, Tianhao Qi, Jiawei Liu, Mingzhen Sun, Pengqi Tu, Tianxiang Ma, Fei Dai, Songtao Zhao, Siyu Zhou, Qian He
ICCV 2025.
[Paper][Project Page]

Mengtian Li*, Jinshu Chen*, Wanquan Feng *†, Bingchuan Li, Fei Dai, Songtao Zhao, Qian He
CVPR 2025.
[Paper][Project Page][Code]

Tianhao Qi, Jianlong Yuan, Wanquan Feng, Shancheng Fang, Jiawei Liu, SiYu Zhou, Qian He, Hongtao Xie, Yongdong Zhang
CVPR 2025.
[Paper][Project Page][Code]
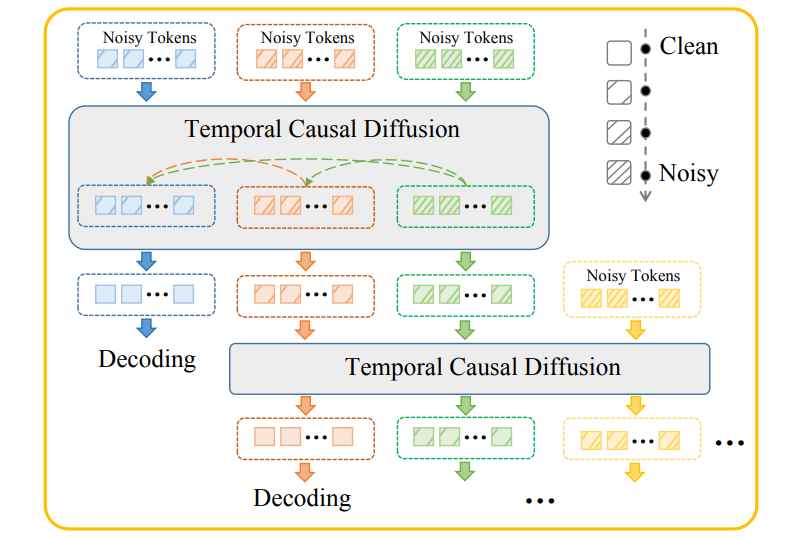
Mingzhen Sun, Weining Wang, Gen Li, Jiawei Liu, Jiahui Sun, Wanquan Feng, Shanshan Lao, SiYu Zhou, Qian He, Jing Liu
CVPR 2025.
[Paper][Project Page][Code]

Xinghui Li, Qichao Sun, Pengze Zhang, Fulong Ye, Zhichao Liao, Wanquan Feng †, Songtao Zhao †, Qian He
CVPR 2025.
[Paper][Project Page][Code]

Wancheng Feng, Wanquan Feng, Dawei Huang, Jiaming Pei, Guangliang Cheng, Lukun Wang †
Preprint.
[Paper]

Wanquan Feng †, Jiawei Liu, Pengqi Tu, Tianhao Qi, Mingzhen Sun, Tianxiang Ma, Songtao Zhao, Siyu Zhou, Qian He
ICLR 2025.
[Paper][Project Page][Code]
2024
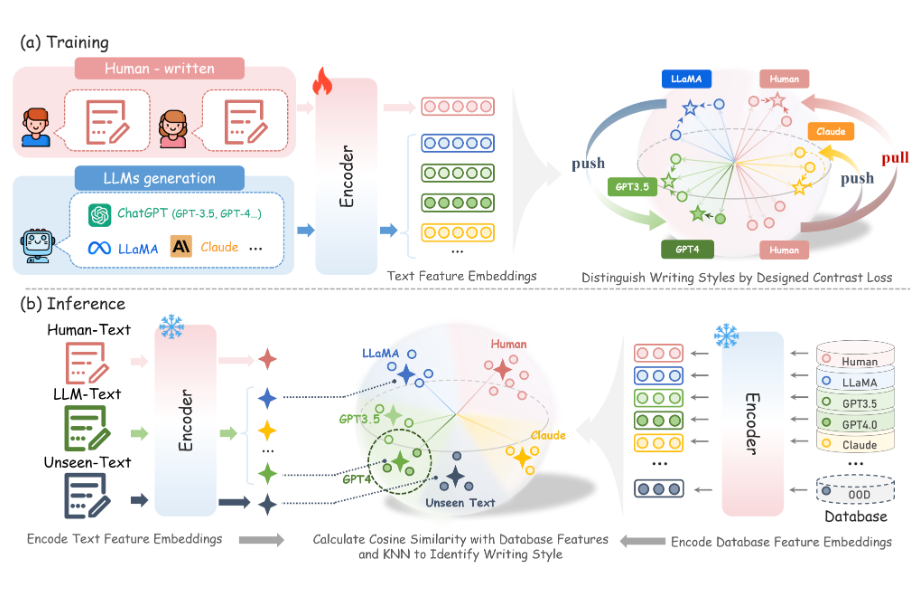
2023
Haotian Yang, Mingwu Zheng, Wanquan Feng, Haibin Huang, Yu-Kun Lai, Pengfei Wan, Zhongyuan Wang, Chongyang Ma †
SIGGRAPH Asia 2023.
[Paper][Project Page]
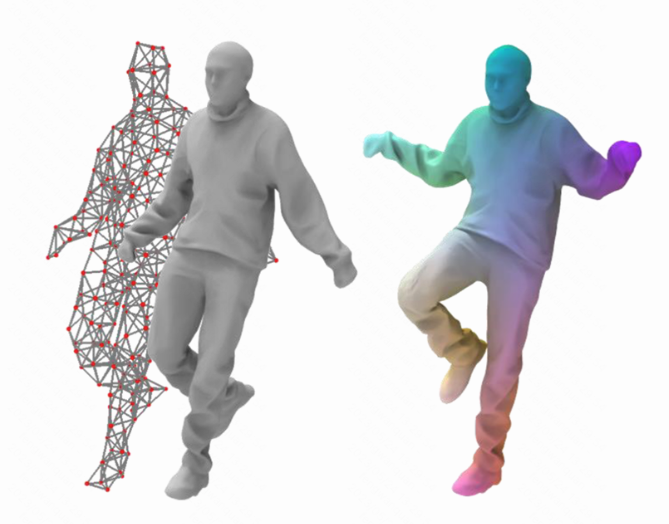
2022

Wanquan Feng
Ph.D. Thesis.
[Paper (Full text in Chinese)]

Hongrui Cai, Wanquan Feng, Xuetao Feng, Yan Wang, Juyong Zhang †
NeurIPS 2022.
[Paper][Project Page][Code]
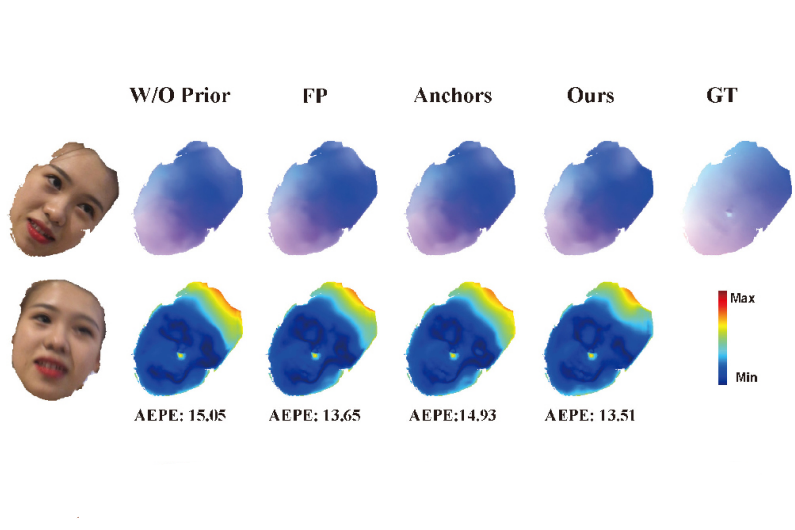
Zhuang Peng, Boyi Jiang, Haofei Xu, Wanquan Feng, Juyong Zhang †
CVM 2022.
[Paper]
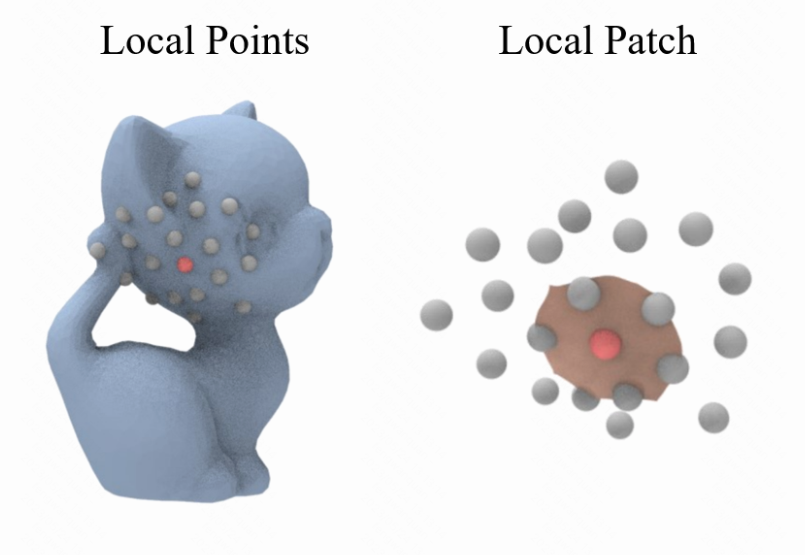
Wanquan Feng, Jin Li, Hongrui Cai, Xiaonan Luo, Juyong Zhang †
CVPR 2022.
[Paper][Project Page][Code]
2021

Wanquan Feng, Juyong Zhang †, Yuanfeng Zhou, Shiqing Xin
TVCG 2021.
[Paper]

Wanquan Feng, Juyong Zhang †, Hongrui Cai, Haofei Xu, Junhui Hou, Hujun Bao
CVPR 2021.
[Paper][Project Page][Code]